Table of contents
- Determine the API format.
- Define the resources and actions on them.
- Define the API endpoints.
- Consider input validation and error handling.
- Consider endpoint performance.
- Enable API caching.
- Determine if the API is public or private.
- Determine if the API requires access restrictions for endpoints.
- Determine how to handle traffic shaping
- Decide how to manage API evolution and versioning.
Design the internal and external APIs
API considerations
- Use an API description language like OpenAPI/Swagger, RAML etc. This serves as a single source of truth for all aspects of API design and development, for example generated documentation and contract-first design.
- Design self-explanatory, intuitive and predictable APIs.
- Provide good, human-readable and up-to-date documentation.
- Handle unexpected input in a graceful way (forward-compatibility).
- Maintain older versions of the API and deprecate them (backward-compatibility).
- Ensure the API can only be consumed by authenticated and authorised consumers.
- Ensure the API does not leak internal information. For example, an API should not expose numeric order numbers to make it easy for competitors to guess order volumes.
- Ensure that the API is reusable across consumers and projects.
- Choose between a stateful (maintaining session IDs in between calls) or a stateless pattern (every request provides all the necessary information). Stateless APIs could offer better scalability and availability.
REST considerations
- Use plural nouns for resources
HTTPverbs to operate on resources - Consider filtering over nesting: nesting enforces relationships that could change and changing APIs is hard, e.g.
/payments?subscription=xyzvs/subscriptions/xyz/payments
Determine the API format.
Representational State Transfer (REST) is the most common and assumed in the rest of the checklist.
- REST
- HATEOAS
- GraphQL
- RPC (Remote Procedure Call)
- SOAP
- XMPP (Extensible Messaging and Presence Protocol)
- Web sockets
Define the resources and actions on them.
Define the API endpoints.
Consider input validation and error handling.
Consider separating validation errors from integration errors:
Integration error:
{
"error": {
"id": "ERROR_ID",
"type": "access_forbidden",
"code": 403,
"message": "You don't have the right permissions to access this resource",
"documentation_url": "https://api.company.com/docs/errors#access_forbidden",
"request_url": "https://api.company.com/requests/REQUEST_ID",
"request_id": "REQUEST_ID"
}
}
Validation error:
{
"error": {
"top errors here": "...",
"errors": [{
"field": "sort_code",
"reason": "missing_field",
"message": "Sort code is required"
}]
}
}
- Create input cleaning and validation rules to prevent common attacks
- Define error codes and consistent error message style (i.e. format, encoding)
Consider endpoint performance.
Consider using cursors over limit/offsets:
before: the ID of the first object returned (start of page)after: the ID of the last object returned (end of page)count: the maximum number of objects to return
Benefits:
- Prevents missing or duplicated records for growing collections.
When where writes happen at a high frequency, the overall position of the cursor in the set might change.
- Prevents large offsets from hitting the database performance.
Using offset doesn’t work well for large datasets, since the database still needs to read up to offset but discard it. With a cursor, the database only fetches the rows after a specific reference point.
The query could ask for count + 1, in order to use the next id as next cursor.
SELECT * from payments
WHERE account_id = ?
ORDER BY payment_id DESC
LIMIT (count + 1)
{
"results": [...],
"paging": {
"before": "<id>",
"after": "<id>",
"count": 100
}
}
Consider supporting asynchronous requests for long running operations like payment processing and emails, using a query param async=true.
This helps make the error and retry logic a bit easier. The async request returns immediately with a URI which will have the results when they’re ready. The API can support a pull or push approach.
For polling, consider replying with different status when the request is new or existing.
| Request status | Response |
|---|---|
| Found | HTTP 200 OK - request has been completed |
| Not found | HTTP 202 Accepted - request is in progress; send a location to check the status and optionally, a retry-after for polling interval |
For push-based, consider passing a webhook_uri to receive a notification when the request has completed. For easier versioning, the payload of results_uri would return resources IDs rather than serialised objects. This way, resources can be queried using the appropriate API version.
curl -H "Authorization: Bearer ${access_token}" \
-H "Api-Version: 2021-01-01" \
"https://api.example.com/some_data/${data_id}?async=true&webhook_uri=${uri}"
{
"results_uri": "https://api.example.com/2020-01-01/results/1c367b88-49b1-48b5-a08e-49b6ac2d07b0",
"status": "Queued",
"task_id": "1c367b88-49b1-48b5-a08e-49b6ac2d07b0"
}
| Status | Description |
|---|---|
| Queued | The request has been acknowledged and waiting to run |
| Running | The request is in progress |
| Succeeded | The request has successfully terminated |
| Failed | The request has failed |
- Define pagination style to improve performance
- Enable content compression to reduce latency and bandwidth
- Support for asynchronous requests
Enable API caching.
How a web cache works
- Generally, if the server responds with non-cacheable headers or the request is authenticated or a
POST(controversial), the content won’t be cached. - If the cached object is fresh e.g. is within the expiry date, the cache will return it to browsers without checking the server.
- If the cached object is stale, the server will be asked to validate the copy. If the server is not available, the stale object might still be returned.
Cache control headers
There are two main headers to control web caches Cache-Control and Expires.
Cache-Control is mandatory, it switches on caching. Without it, nothing works. It’s a composite header with multiple allowed values:
max-age=[seconds]: the max amount of time relative to the time of the request that the requested resource is considered fresh; similar toExpirespublic: normally, if a request is authenticated, responses are private; this marks authenticated responses as cacheable for both browser and other proxy cachesprivate: allows browser caches to store the responseno-cache/no-store: forces the browser not to cache the resource and ask the server every timemust-revalidate: tells the browser cache not to serve a stale response if it can’t communicate with the server
Cache request and response headers
Last-ModifiedandIf-Modified-Sinceare time-based headers:
// <- Response
Cache-Control:public, max-age=31536000
Last-Modified: Mon, 01 Jan 2021 17:45:57 GMT
// -> Request
If-Modified-Since: Mon, 01 Jan 2021 17:45:57 GMT
The client can use the pair If-Modified-Since request
ETagandIf-None-Matchare hash-based headers:
// <- Response
Cache-Control:public, max-age=31536000
ETag: 15f0fff99ed5aae4edffdd6496d7131f
// -> Request
If-None-Match: 15f0fff99ed5aae4edffdd6496d7131f
The server returns a HTTP 304 - Not Modified header with an empty body if the resource is still fresh.
- Determine what can be cached on the API side
- Determine what can be cached on the client-side
- Cache regular and admin access separately
Determine if the API is public or private.
- The API is consumed by internal services inside an organisation
- The API is consumed by external clients inside an organisation, like a mobile app
- The API is consumed by external third-party applications outside the organisation
Determine if the API requires access restrictions for endpoints.
- API has IP CIDR restrictions, e.g. only clients inside an internal network are allowed
- API has location restrictions (geofencing), e.g. mobile clients using GPS, 3/4/5G, Wifi triangulation
- API has time restriction, e.g. only within business hours
- API has request rate restriction (i.e. throttling limit)
- API has maximum number of requests restriction (i.e. quota limit)
Determine how to handle traffic shaping
 |
|---|
| API Traffic shaping |
Traffic shaping can be used to guarantee a minimum level of performance for all consumers when the load on the API is high. It also helps against Denial of Service (DoS) attacks or clients who bombard the API with requests because of bugs.
The most common form of traffic shaping is rate limitation. The parameters for implementing it are:
- A time window for limiting requests
- A counter of the requests in the current time window
- A maximum number of requests allowed per time window
If the counter exceeds the maximum, further requests can be: a) rejected with a 429 Too Many Requests code and some useful headers to inform the client about the remaining limit and reset window b) delayed, e.g. put in a queue with a fixed length.
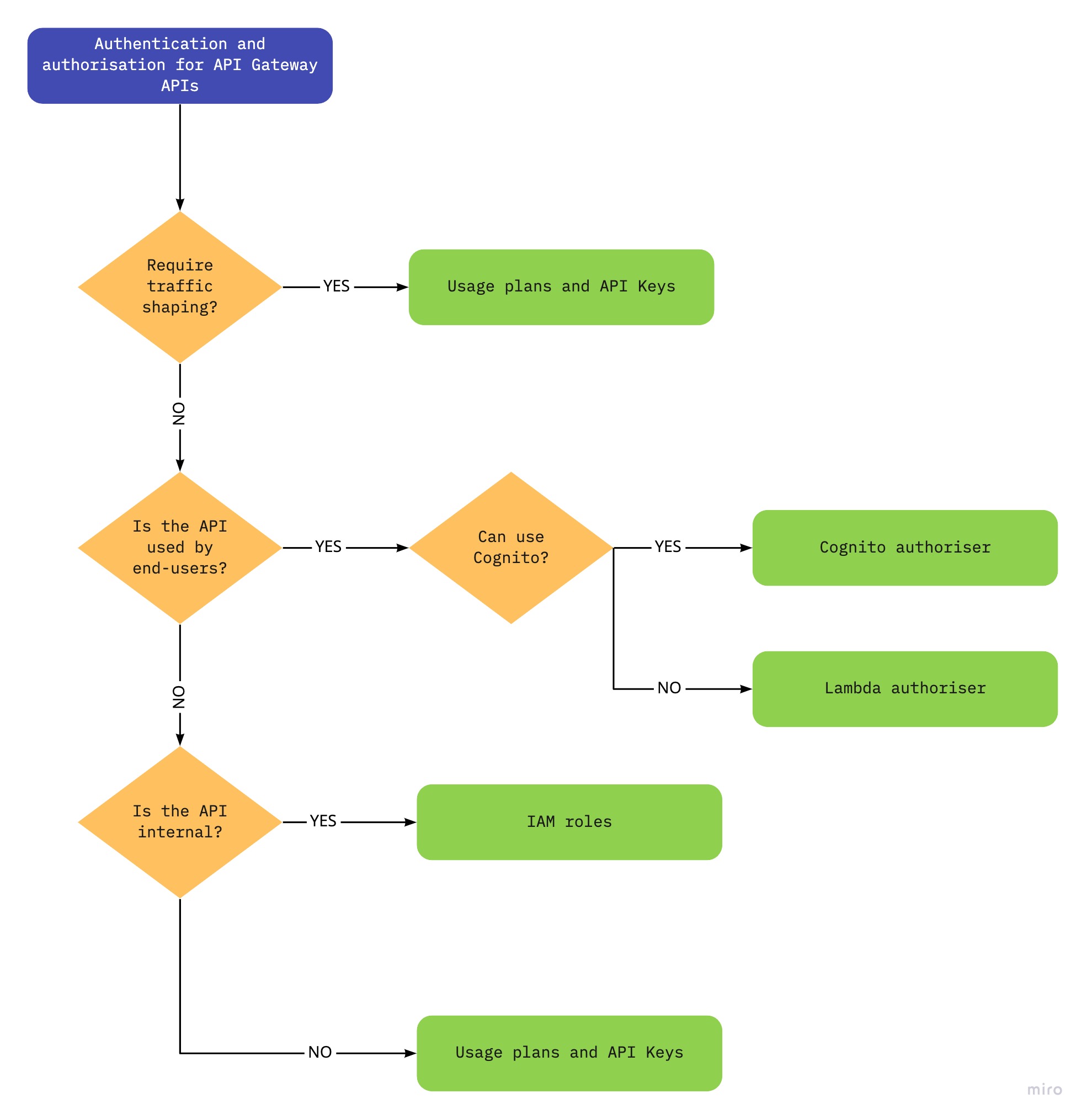
Note: Even if you use API Keys and Usage Plans you still require authentication and authorisation for your API clients. Otherwise, a client with a valid API Key can access all your APIs in that usage plan. For authentication and authorisation on AWS you can use IAM, a Lambda authoriser or Cognito user pool.
Throttling vs quotas Throttling refers to limiting the amount of requests per second, while quotas allow a certain amount of API calls over a longer period, e.g. montly. Quotas might need to be automatically or manually reset.
- Use API throttling
- Use client quotas
Decide how to manage API evolution and versioning.
Creating APIs is a lot more waterfall than agile. APIs are hard to change well.
- In a distributed system, the responsibility is shared across multiple teams who need coordination.
- Once the API is published, changing it requires either forcing clients to update or maintaining previous versions to avoid breaking contract.
Opinionated considerations
- Use versions as dates
2021-01-01and submit them as headersApi-Version: 2021-01-01; numbering likev1,v2are not as expressive to indicate how old the requested version is - Promote incremental improvement
-
For webhooks, avoid including serialised resources and instead use resource IDs; the client has the choice to request the appropriate version.
- Maintain old versions for at least 6 months
- Define the lifecycle of the API e.g. publishing stages, split testing etc.
- Define the versioning policy